This article is more than 5 years old.
On Friday Erik & Sarah watched a webinar sponsored by the Berkman Center for Internet & Society at Harvard University. The speaker was Lee Dirks, the Director, Education & Scholarly Communication at Microsoft External Research.
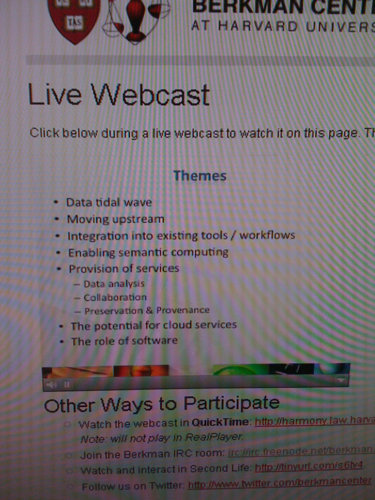
Lee discussed the future of scholarly communication, touching on issues of preserving the entire research process (including background research, testing, collaboration, etc). He also talked about the role that linked data and complex community-based data analysis sites such as Swivel and Freebase are doing to create a new type of research archive.
His themes also included cloud computing, linked data, and preservation and archiving, and new publication mechanisms including Data.gov, SciVee, Mendeley/Papers, and Jove (Journal of Visualized Experiments). His discussion of these sites was cursory but touched on some really neat ways in which machine readable data is being used to create/preserve knowledge.
He touched on SmugMug, Google Wave, and other cloud based sites on the way to talking about Duraspace/Duracloud as examples of new approaches to archiving and providing services for complex data.
He concluded with the observation that there is still a gap between what these systems are capable of and what researchers and scientists know/think about e-research and the role it plays in science, peer review, and publication.
During the Q&A a discussion about data-aggregation sites included Fluxnet and Dataverse, a data harvesting and preservation site (similar it appears to the Internet Archive) that provides cloud solutions for the archiving and preservation problem that Lee said was one of the goals of Duracloud.
The most provocative comment of the session (roughly quoted) was:
“The safe world of collecting books and scholarly journals has been done…data curation, provision of services, working with publishers, and working with scholars…grey literature…that is the stuff we need to apply our skills to.”
Inevitably, this raised the question of “what makes a good librarian?” The answer focused on a ‘service orientation’ that builds services on top of data that includes business, informatics, legal, and technology training.
Interested in more? the NSF report on Data in the 21st Century is a good place to start!
1 Comment on ‘Berkman Center for Internet & Society Webinar – Lee Dirks’
Thanks for the abundance of related links to pursue. There’s a lot here to explore and the topic is really relevant as we bring in our first Scholarly Communication Librarian to shape a meaningful initiative.