This article is more than 5 years old.
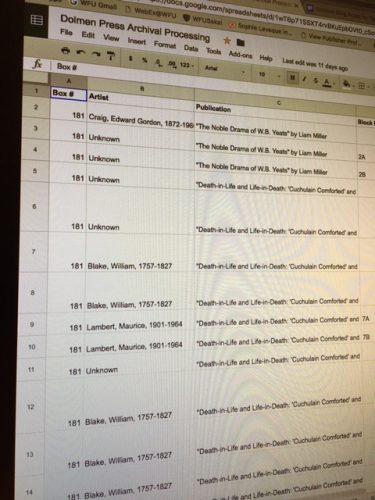
When we last left off, I had spent many hours (hundreds?) creating data while processing the collection. Now I had to clean up my own work. I should mention, I have not yet earned my master’s in library and information science. I am due to begin this September at University College Dublin in Ireland. As a novice, I learned some things the hard way during the standardization part of this project. Our Collections Archivist, Stephanie Bennett, was patient with me as I toiled with a monster of my own making. Because my excel sheet would be the basis for a new finding aid (generated in Archivists’ Toolkit software) it was very important that my data was in a form that Stephanie could wrangle later.
I was surprised to learn that the finding aid wouldn’t highlight all of what I had tracked. The finding aid inventory would only list box number, block number, and a brief item title that might include some combination of artist name, publication, image title (a description of the image on the plate), and medium. That meant that my columns for description (notes from the back of the plate and/or bibliographic citations for further information on the image), publication call number, a link to a photo of the plate, and subject tags (if it included religious imagery or a woman) would not be shown. I didn’t have time to worry about wasted efforts, I had to get my data whipped into shape.
First, I had to change all of the names of artists to last name, first name, and confirm the name in the Library Of Congress Authorities database. It is important to use a controlled vocabulary to ensure accessibility. There were a number of artists that I could not confirm (and I recorded who they were), but I was surprised to find that most of the artists were in the Library of Congress. This process was a little tedious, but considering there was only 53 artists total, it was an easy task to complete.
The next part was very painful to my ego. I had to actually clean up my data by deleting extra spaces, making sure I used the same terms consistently, and in general making sure everything was consistent. Imagine a series of comic book frames of me facepalming myself while staring at a computer. My gusto for the project was challenged by the sheer grit it took to sort through everything.
How could I use a comma so inconsistently? Why did I sometimes capitalize the first letter of every word and sometimes not? Why did I alternate between the terms “guy” and “man”? Why didn’t I put ANY of the titles in quotation marks?
And so on. Through this data clean up, I learned the value of setting parameters before a project begins. For instance, I wish I had thought more carefully about the vocabulary I was using. Considering Dublin Core metadata standards before I began would have been much easier than having to make my data fit the fields after its creation. I also wish that at the outset, I had been more aware of how important it was for me to be careful. Collections don’t often get a second pass, and it wasn’t until I was almost finished that I appreciated the gravity of my choices whether it be how I described an image or if I had interpreted a detail correctly.
After standardization, I began to work on the application of the data. This is where the information that wasn’t going to be in the finding aid would be used. Shortly after beginning processing, I met with our digital humanities expert, Dr. Carrie Johnston, about possible digital platforms that may be helpful gateways to access the plate collection. Dr. Johnston suggested building an Omeka S site to highlight the metadata I was creating, allowing future scholars to sort through the collection by subject matter or artist.
I really liked the idea of an “exhibit” space for the images. I was lucky enough to have spent months looking through the collection and appreciated that you can only see trends in imagery between artists and subject matters by seeing everything together.
We tried Omeka. Unfortunately, because our Dolmen images are still copyrighted, the password-protected links that I had painstakingly entered for each plate would not load correctly on the site. After all of the time spent resizing images and trying to figure out what kind of upload link would work in Omeka, my hopes for a digital collection were dashed. For the record, link specifications should be figured out BEFORE you process your thousand-plus object collection because Omeka has strict standards.
Sadly, Omeka wasn’t the right digital tool for the collection’s specifications. We have the images saved and the prints are easy enough to look through, but I did feel a little heartbroken about all the work I had done that seemed to have turned into nothing. I tagged images to create two Omeka exhibits: one for women or genderless figures and the other for overt Christian imagery. These tags still exist in the metadata, and I hope they will be useful to researchers in the future.
I could not wrap this project up in a neat bow. It took introspection to understand that this collection was going to survive long after my time at ZSR and my lifetime. A bow to wrap the project up in the short term wasn’t feasible and isn’t with many archival processing projects. In my next post, I will analyze some of the trends I saw throughout the images, data about the artists, and points of interest in the collection.
4 Comments on ‘Dolmen Printing Plates Processing Adventure: Part 2’
Sophie, I admire your fortitude on this project. Someday it will be an accessible treasure thanks to your hard work. Thank you from this history buff.
Sorry you had to learn more about dirty data the hard way! You now have a thorough fundamental understanding of dirty data and some basic tenets of technical services work that can help you in your career. I wish you well in your future endeavors and I look forward to your next post!
Great work Sophie- congratulations!
Sophie, I know the learning curve on this project was steep, and at times painful, but you are well ahead of many of your future classmates and colleagues in learning the hard lessons about what needs to be identified FIRST. And even when you think you know it all upfront, you often find you don’t…that’s part of the “fun,” right?!