
This article is more than 5 years old.
New (fiscal) year, new… collections management tool. As I mentioned in my recent post about newly processed collections, SCA and especially I have been busy adopting a new tool to help us manage our materials.
Our collections management covers physical control of collections: how many boxes or oversize objects make up a collection, where all of those are physically found. These systems also support intellectual control of collections, like helping us keep lists of local and Library of Congress-approved subject headings and controlled names that we use to categorize and describe materials. Without these digital memory banks, for example, differentiating pictures of and information about long-time English professor Edgar E. Folk (1897–1982) from his alumnus father Edgar E. Folk (1856–1917) or the proceeding additional generations of E. E. Folks would become, well, impossible.
Our old collection management system, Archivists’ Toolkit (AT), was created by a group of institutions and funded by Mellon grant funding; these archivists and developers were assisted, as all of these programs are, by many testers who worked to make the software functional. AT is a bit old school now, a database that required downloading the software (so old-fashioned) that ZSR’s Technology Team kept running like clockwork. But prior to AT’s existence, if archivists wanted to put our collection finding aids online (and we did, because The Internet), we had to hand-encode them in HTML’s cousin-language XML, closing every quote mark and angly bracket to create something that looks like this:
<controlaccess>
<head>Occupations</head>
<occupation encodinganalog=”656″ source=”aat”>Dancers.</occupation>
<occupation encodinganalog=”656″ source=”lcsh”>Dance teachers.</occupation>
</controlaccess>
<dsc type=”combined”>
<head>Collection Contents</head>
<c01 level=”file”><did><container type=”box-folder” label=”Box “>1 : 1</container>
<unittitle>Biographical and academic materials</unittitle></did>
<c02 level=”file”><did><container type=”box-folder” label=”Box “>FB-21 : 1</container>
<unittitle>Boston Girls’ High School, commencement program</unittitle>
<unitdate normal=”1918″>1918</unitdate>
</did></c02>
(It is a testament to my graduate school professors and me that I can actually understand that pretty well.) You can now see why, in fact, AT’s interface was the height of 2009 fashion when it debuted:
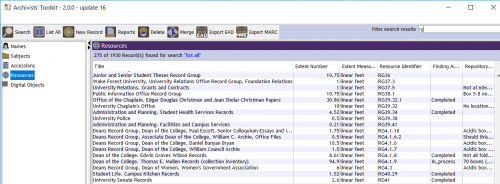
Human-readable! No angled brackets in sight. We had a couple of options to replace AT as its usefulness waned, but its closest relative is the system we went with, ArchivesSpace (ASpace). Like AT, ASpace is an open-source application, though it is funded through a membership model that will hopefully encourage a longer lifespan that AT had. It’s also a web-based application, meaning it’s more Pandora than Napster. And its interface is contemporary, full of with smooth sans-serif fonts:
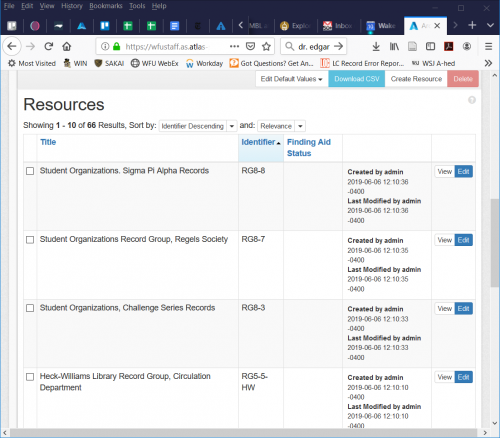
While the data migration from one system to another was smooth thanks to work by Web Services Kevin Gilbertson, Archives Assistant Finley Turner, me, and our vendor Atlas Systems: now we have to look under the hood and figure out how this thing works! I’ve noticed that takes more clicks to get around, and more noticably, the locations of certain fields and the language used has changed. We’re no longer dealing with “Names”; they are now “Agents.” Numerical identifiers are now separated with hyphens instead of periods, which is just weird to my eye.
I won’t bore you with a list of all the differences between the systems, but with these changes big and small, I have to determine how we will use ASpace. Will our procedures shift wildly? No, thankfully. And plenty of other organizations are using ASpace, so there is documentation to read and colleagues to call with questions.
But in order to make sure that everyone in SCA is using the system as similarly as possible, I have to codify which information goes into each field, which fields we won’t use, what other tools we will add in to make our lives a little better (hopefully!). And then everyone else needs to get comfortable with ASpace, too, since it’s our main tool for serving up materials for people seeking informaiton and coming through our Research Room. During the school year, student workers use it every day as well. Basically, now that we’ve got a new kind of oven, we’ve got to figure out practical, efficient ways for us, together, to bake bread and make nachos – or process and provide access to collections – in it. Wish us luck!
4 Comments on ‘Updating Tools and Testing New Ovens: Changes to Collections Management in SCA’
What a great explanation of the diff’s between AT and ASpace – thank you. I look forward to making open sourced nachos with no angled brackets!
Thanks for this expansive explanation! I think I get it now!
Super exciting to see this coming together. This should bring some really positive and welcome changes!
Thank you for the informative explanation.